GPU Hairline 极细描边
Hairline(极细描边)是 tgfx 中专门用于渲染宽度为 1 像素或更细线条的 GPU 加速方案。该方案绕过常规的三角化流程,直接在 GPU 上通过 Coverage 计算实现亚像素级抗锯齿,在保持高质量渲染的同时大幅提升性能。
1. 方案概述
1.1 设计目标
Hairline 渲染方案专为以下两个核心场景设计:
Hairline 描边模式:无论画布如何缩放,始终按 1 物理像素 宽度渲染线条,常用于 UI 分隔线、网格线等需要保持视觉一致性的场景
亚像素描边降级:当缩放后实际描边宽度小于 1 像素时,自动按 1 物理像素 渲染,同时 降低透明度 以模拟更细的视觉效果,实现平滑的缩放动画过渡
这两个场景中,曲线渲染采用 Loop-Blinn 算法,相比传统三角化方案具有更高的渲染性能:
- CPU 端三角面化计算量极低:每条曲线仅需生成固定数量的顶点,无需传统方案中基于曲率的迭代细分与拟合计算
- 顶点数据量大幅减少:更小的 Vertex Buffer 带来更低的显存占用,同时减少 CPU 到 GPU 的数据传输带宽消耗
1.2 技术特点
优势:曲线渲染在 Shader 中完成,CPU 端三角面化计算更简单
- 普通描边:需要为每条路径生成完整的描边轮廓,描边轮廓基于曲率拟合成直线三角面
- Hairline 渲染:基于"一条曲线一组三角面"的简化策略
- 直线:6 个顶点形成菱形区域(2 个内部顶点 + 4 个外部顶点)
- 曲线:5 个顶点形成五边形区域(1 个内部顶点 + 4 个外部顶点)
- Stroke Path 无需宽度计算,也无需处理复杂的连接点(join)和端点(cap)计算
- 三角面化计算量显著减少,CPU 开销更低
劣势:GPU 端渲染批次更多
- 普通描边:所有顶点在一个 Vertex Buffer 中,一次渲染批次完成绘制
- Hairline 渲染:直线和曲线分别处理,使用两个独立的 Vertex Buffer
- Buffer 1:所有直线段的三角面
- Buffer 2:所有曲线段的三角面
- 需要两次渲染批次(Draw Call),GPU 调度开销增加
性能权衡
| 维度 | 普通描边 | Hairline 渲染 | 影响 |
|---|---|---|---|
| CPU 三角面化 | 复杂(曲线按直线剖分拟合成三角形) | 简单(一条曲线生成一组三角面) | Hairline 优势 |
| Vertex Buffer | 单个 Buffer | 两个 Buffer(直线/曲线) | 普通描边优势 |
| 渲染批次 | 1 次 Draw Call | 2 次 Draw Call | 普通描边优势 |
| GPU 光栅化 | CPU 生成轮廓后 GPU 填充 | GPU Shader 直接计算曲线和抗锯齿 | Hairline 优势 |
综合结论:尽管 Hairline 增加了渲染批次,但 CPU 端计算简化 + GPU Shader 优化带来的性能收益远超过额外 Draw Call 的开销,尤其在复杂路径和单线程场景下优势明显。
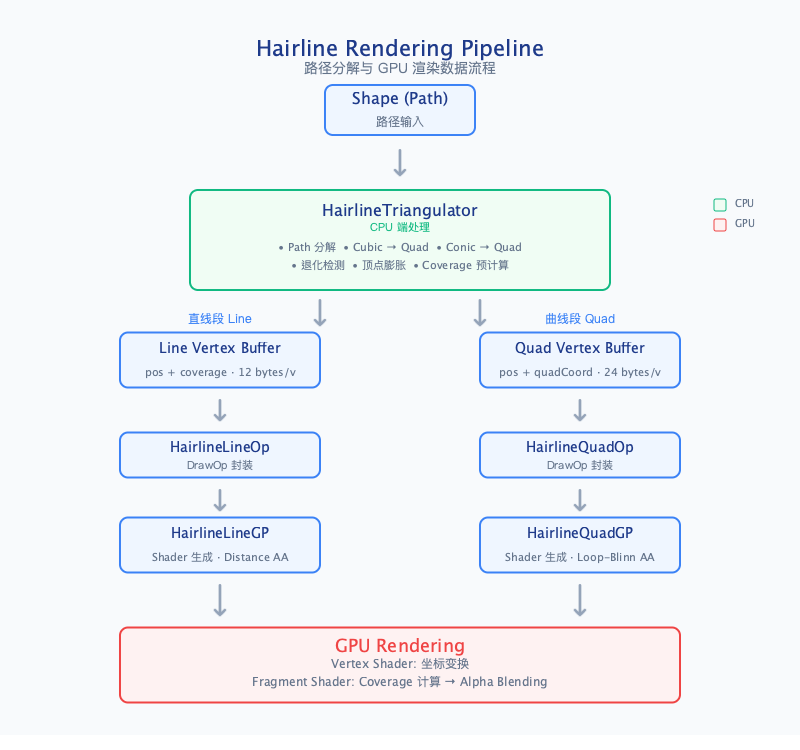
1.3 核心架构
Hairline 渲染采用分治策略,将路径分解为直线段(Line)和二次贝塞尔曲线(Quad)两类几何体,分别由专用的 DrawOp 处理。路径分解规则如下:
- 直线段:保持原始几何形态,直接生成直线三角面
- 曲线段:三次贝塞尔曲线(Cubic)和圆锥曲线(Conic)统一转换为二次贝塞尔曲线(Quad),简化 Shader 实现复杂度
Path (Line / Quad / Cubic / Conic)
│
▼
HairlineTriangulator (CPU)
│
├──► Line ───────────────────────────► Line Vertices ──► HairlineLineOp ──► GPU Shader
│
└──► Quad / Cubic / Conic ──► Quad ──► Quad Vertices ──► HairlineQuadOp ──► GPU Shader
1.4 数据流程图
1.5 Loop-Blinn 算法原理
Hairline 方案中二次曲线的渲染采用 Loop-Blinn 算法,该算法由 Charles Loop 和 Jim Blinn 在 SIGGRAPH 2005 论文 "Resolution Independent Curve Rendering using Programmable Graphics Hardware" 中提出。
核心思想:将二次贝塞尔曲线转换为隐式方程形式,在 Fragment Shader 中直接求解曲线内外关系,无需传统的曲线细分拟合。 该算法基于一个关键的数学性质:所有二次贝塞尔曲线在射影几何下是等价的,即任意二次曲线都可以通过射影变换映射到同一条规范曲线 $u^2 - v = 0$。GPU 的透视校正插值天然实现了这一逆映射,使得 Shader 只需在规范空间中完成简单的求值运算。
隐式方程:对于二次贝塞尔曲线,定义隐式方程 $F(u,v) = u^2 - v$:
- $F < 0$:点在曲线内侧
- $F = 0$:点在曲线上
- $F > 0$:点在曲线外侧
UV 坐标映射:在 CPU 端为曲线控制点分配特殊的纹理坐标 $(u, v)$,GPU 硬件自动对这些坐标进行插值。Fragment Shader 仅需一次乘法和一次减法即可完成曲线求值,计算效率极高。
抗锯齿:利用屏幕空间偏导数(dFdx/dFdy)计算隐式函数的梯度,将 $F$ 值归一化为像素距离,实现亚像素级平滑过渡。
参考文献:
2. Vertex Buffer 布局
2.1 Line Vertex Buffer 布局
每条直线段生成 6 个顶点、构建 6 个三角形,形成以线段为中心的菱形包围区域。其中 p0、p1 位于线段两端点,作为内层顶点(coverage = 1.0);p2~p5 沿线段法线方向向外扩展 1 个像素,形成外层顶点(coverage = 0.0)。GPU 在光栅化时对 coverage 进行线性插值,实现从线段中心向边缘 1 像素范围内的平滑过渡,完成抗锯齿效果。
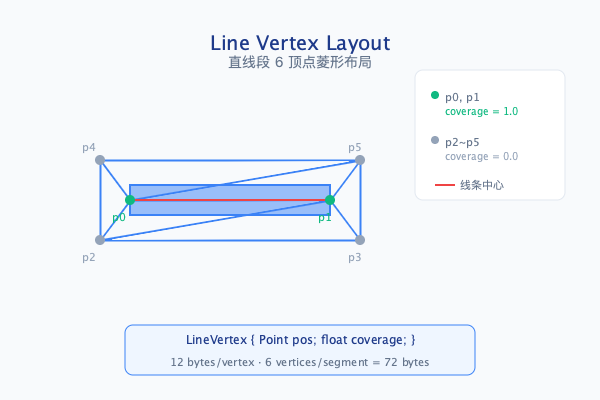
数据结构:
struct LineVertex {
Point pos; // 8 bytes (x, y)
float coverage; // 4 bytes
};
// Total: 12 bytes per vertex
// 6 vertices per line segment = 72 bytes per line
三角形构建:
6 个顶点通过索引构建 6 个三角形,共 18 个索引。三角形划分策略确保每个三角形至少包含一个内层顶点(p0 或 p1),使 coverage 插值能够正确覆盖整个菱形区域:
索引列表: (p0,p2,p4), (p0,p4,p1), (p1,p4,p5), (p1,p5,p3), (p0,p1,p3), (p0,p3,p2)
三角形分布:
- 左端区域: (p0,p2,p4) - 覆盖左侧外扩三角
- 中央上部: (p0,p4,p1) - 连接两端点与上外层
- 右上区域: (p1,p4,p5) - 覆盖右上外扩
- 右端区域: (p1,p5,p3) - 覆盖右侧外扩三角
- 中央下部: (p0,p1,p3) - 连接两端点与下外层
- 左下区域: (p0,p3,p2) - 覆盖左下外扩
2.2 Quad Vertex Buffer 布局
每条二次贝塞尔曲线生成 5 个顶点、构建 3 个三角形,形成包围曲线的五边形区域。其中 a0、a1 为曲线两端点,b0 为曲线控制点(凸包顶点),这三个顶点位于曲线本身;c0、c1 分别从端点沿曲线法线方向向外扩展 1 个像素,形成抗锯齿边缘。GPU 通过 Loop-Blinn 算法在 Fragment Shader 中计算每个片元到曲线的隐式距离,实现亚像素级精度的抗锯齿效果。
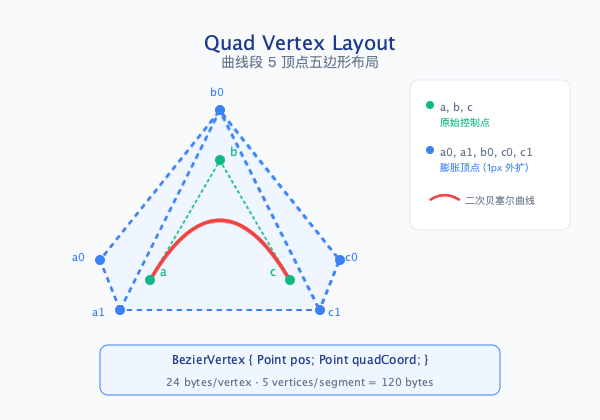
数据结构:
struct BezierVertex {
Point pos; // 8 bytes (x, y) - 顶点位置
Point quadCoord; // 8 bytes (u, v) - Loop-Blinn 隐式方程坐标
};
// Total: 16 bytes per vertex
// 5 vertices per quad segment = 80 bytes per quad
三角形构建:
5 个顶点通过索引构建 3 个三角形,共 9 个索引。三角形划分确保完整覆盖曲线的凸包区域及外扩抗锯齿边缘:
索引列表: (a0, a1, b0), (b0, c1, c0), (a1, c1, b0)
三角形分布:
- 曲线凸包: (a0, a1, b0) - 覆盖曲线主体区域,Loop-Blinn 计算在此三角形内进行
- 左侧外扩: (b0, c1, c0) - 覆盖控制点到左端点的抗锯齿边缘
- 右侧外扩: (a1, c1, b0) - 覆盖右端点到控制点的抗锯齿边缘
3. GPU 端片元着色
3.1 直线段片元着色
对于直线段,CPU 预计算每个顶点到线条中心的距离(edge distance),存入顶点属性。Fragment Shader 只需简单插值和 clamp 操作:
// Vertex Shader: 传递边缘距离
varying float vEdgeDistance;
vEdgeDistance = aEdgeDistance; // 从顶点属性获取
// Fragment Shader: 计算 Coverage
float edgeAlpha = abs(vEdgeDistance);
edgeAlpha = clamp(edgeAlpha, 0.0, 1.0);
gl_FragColor = uColor * vec4(edgeAlpha);
3.2 二次曲线片元着色(Loop-Blinn 算法)
二次曲线采用 Loop-Blinn 隐式方程(参见 1.5 节原理说明)在 Fragment Shader 中计算覆盖率:
// Fragment Shader: Loop-Blinn 曲线抗锯齿
vec2 duvdx = dFdx(vHairQuadEdge.xy);
vec2 duvdy = dFdy(vHairQuadEdge.xy);
// 计算隐式函数梯度 ∇F
vec2 gF = vec2(
2.0 * vHairQuadEdge.x * duvdx.x - duvdx.y,
2.0 * vHairQuadEdge.x * duvdy.x - duvdy.y
);
// 计算隐式函数值 F = u² - v
float F = vHairQuadEdge.x * vHairQuadEdge.x - vHairQuadEdge.y;
// 归一化距离并转换为 Coverage
float edgeAlpha = sqrt(F * F / dot(gF, gF));
edgeAlpha = max(1.0 - edgeAlpha, 0.0);
4. 直线与曲线分治策略
4.1 分离设计的动机
HairlineLineOp 和 HairlineQuadOp 采用分离设计,主要基于以下考虑:
| 维度 | HairlineLineOp (直线) | HairlineQuadOp (曲线) |
|---|---|---|
| 顶点布局 | 12 bytes (pos + coverage) | 24 bytes (pos + quadCoord) |
| 顶点数量 | 每段 6 顶点 | 每段 5 顶点 |
| 索引数量 | 每段 18 索引 | 每段 9 索引 |
| Shader 复杂度 | 简单(线性插值) | 复杂(dFdx/dFdy + 隐式方程) |
| GPU 指令数 | ~10 条 | ~30 条 |
4.2 分离带来的优势
- Shader 编译优化:GPU 驱动可以为不同复杂度的 Shader 生成更高效的机器码
- 顶点带宽优化:直线段不需要额外的 UV 坐标,减少 50% 顶点数据量
- 批处理效率:相同类型的几何体可以合并绘制调用
- 调试便利性:问题更容易定位到具体的几何类型
4.3 路径分解流程
// PathDecomposer 分解逻辑
switch (segment.verb) {
case PathVerb::Line:
// 直接添加到 lines_ 容器
processLine(segment.points);
break;
case PathVerb::Quad:
// 检测退化并分类
if (IsDegenQuadOrConic(points)) {
// 退化为直线
addToLines(points);
} else {
// 保持为曲线
addToQuads(points);
}
break;
case PathVerb::Cubic:
// 转换为多个二次曲线
auto quads = ConvertCubicToQuads(points);
for (auto& quad : quads) {
addToQuads(quad);
}
break;
}
5. GPUHairlineProxy 与缓存机制
5.1 GPUHairlineProxy 结构
GPUHairlineProxy 是 Hairline 渲染的核心代理类,封装了直线和曲线两个独立的顶点缓冲区:
class GPUHairlineProxy {
Matrix drawingMatrix; // 绘制变换矩阵
std::shared_ptr<GPUBufferProxy> lineVertexProxy; // 直线顶点缓冲代理
std::shared_ptr<GPUBufferProxy> quadVertexProxy; // 曲线顶点缓冲代理
};
5.2 Buffer 缓存与复用机制
// ProxyProvider::createGPUHairlineProxy
auto uniqueKey = shape->getUniqueKey();
// 为直线和曲线分别生成缓存键
auto lineVertexKey = UniqueKey::Append(uniqueKey, &LineVertexType, 1);
auto quadVertexKey = UniqueKey::Append(uniqueKey, &QuadVertexType, 1);
// 查找缓存
auto lineVertexProxy = findOrWrapGPUBufferProxy(lineVertexKey);
auto quadVertexProxy = findOrWrapGPUBufferProxy(quadVertexKey);
// 缓存命中时直接复用
if (lineVertexProxy || quadVertexProxy) {
return std::make_shared<GPUHairlineProxy>(...);
}
// 缓存未命中,创建异步任务生成数据
auto rasterizer = std::make_unique<HairlineTriangulator>(shape, hasCap);
dataSource = DataSource<HairlineBuffer>::Async(std::move(rasterizer));
6. 与普通描边方案对比
6.1 技术路线对比
| 特性 | Hairline 渲染 | 普通描边 |
|---|---|---|
| 曲线处理 | Shader 直接计算(Loop-Blinn) | CPU 端直线拟合 |
| 三角面化 | 简单(一条曲线一组三角面) | 复杂(曲率细分 + 轮廓生成) |
| 顶点数据量 | 较小 | 较大(4-10 倍) |
| Vertex Buffer | 两个(直线 + 曲线) | 单个 |
| Draw Call | 2 次 | 1 次 |
| 抗锯齿计算 | GPU Shader(Coverage) | CPU 生成轮廓 + GPU 填充 |
6.2 优势分析
Hairline 方案核心优势:
- CPU 三角面化简化:一条曲线只需生成一组三角面,无需处理 join/cap/轮廓生成等复杂几何计算
- GPU Shader 曲线拟合零成本:三角形光栅化中 Shader 决定曲线像素是否显示,贝塞尔曲线在 GPU 中并行计算,开销极低
- 更小的顶点数据量:相比普通描边减少 4-10 倍的顶点数据,降低 GPU 内存带宽和上传开销
- 单线程场景优势巨大:CPU 计算简化 + GPU 并行,完全绕过单线程瓶颈,适用于嵌入式设备、WebAssembly 等受限场景
- 抗锯齿开关性能一致:是否抗锯齿在 Shader 中计算,对性能几乎无影响
渲染批次增加的开销可忽略:
- 虽然 Hairline 需要 2 次 Draw Call(直线 + 曲线),普通描边只需 1 次
- 实际场景中:CPU 三角面化简化的收益 >> Draw Call 增加的开销
- GPU 并行能力强,额外的渲染批次对整体性能影响微乎其微
普通描边方案优势:
- 单次 Draw Call:所有顶点在同一 Buffer,渲染批次更少
- 更简单的 Shader:无需 dFdx/dFdy 指令和隐式方程计算
- 多线程友好:复杂的三角面化计算可充分利用多线程并行
6.3 适用场景
- 使用 Hairline:1 像素描边、缩放后宽度小于 1 像素的描边、单线程/低端设备、需要高质量抗锯齿的细线
- 使用普通描边:宽度大于 1 像素的描边、需要处理复杂 join/cap 样式的场景
7. 代码结构
7.1 核心文件清单
src/
├── core/
│ ├── HairlineTriangulator.h # CPU 端路径分解器接口
│ └── HairlineTriangulator.cpp # 路径分解与顶点生成实现
│
├── gpu/
│ ├── proxies/
│ │ └── GPUHairlineProxy.h # GPU 缓冲代理
│ │
│ ├── ops/
│ │ ├── HairlineLineOp.h/cpp # 直线段 DrawOp
│ │ └── HairlineQuadOp.h/cpp # 曲线段 DrawOp
│ │
│ ├── processors/
│ │ ├── HairlineLineGeometryProcessor.h/cpp # 直线几何处理器
│ │ └── HairlineQuadGeometryProcessor.h/cpp # 曲线几何处理器
│ │
│ ├── glsl/processors/
│ │ ├── GLSLHairlineLineGeometryProcessor.h/cpp # 直线 GLSL Shader
│ │ └── GLSLHairlineQuadGeometryProcessor.h/cpp # 曲线 GLSL Shader
│ │
│ └── tasks/
│ └── HairlineBufferUploadTask.h/cpp # 异步缓冲上传任务