渲染管线
一、从一次 draw 调用说起
你调用 canvas->drawRect(...),这行代码执行完,GPU 上发生了什么?
答案是:什么都没有发生。这行代码只是把一条绘制意图记录进了队列——真正的 GPU 工作要等到 context->flush() 才开始。
这不是偷懒,而是 TGFX 渲染管线的核心设计原则:延迟执行、批量提交。理解了这一点,整条管线的每个环节就都有了合理的解释。
二、整体架构
TGFX 的代码分四层,职责清晰,层与层之间边界明确:

include/ 目录是对外的全部 API,其下的 src/ 是实现细节,外部代码不应直接依赖 src/ 里的任何东西。
各模块职责:
| 模块 | 职责 |
|---|---|
core/ | 几何、图像、字体、编解码的平台无关逻辑 |
gpu/ | GPU 资源管理、Op 调度、Shader Program、Backend 适配 |
layers/ | 图层树、DisplayList、脏区、Tile 渲染 |
svg/ | SVG 解析与渲染 |
pdf/ | PDF 导出 |
三、延迟渲染:为什么不立即执行
每次 draw*() 立刻提交 GPU,会有什么问题?
立即执行意味着每次调用产生一次 Draw Call。Draw Call 是 CPU 与 GPU 之间的通信——发出命令、等待 GPU 接收,每次通信都有固定开销,跟画的内容大小无关。如果每个 drawRect 都产生一次 Draw Call,画 200 个矩形就是 200 次通信,而实际上这 200 个矩形可以合并成一次提交。
延迟执行的价值就在这里:攒够了再打,一次打完。
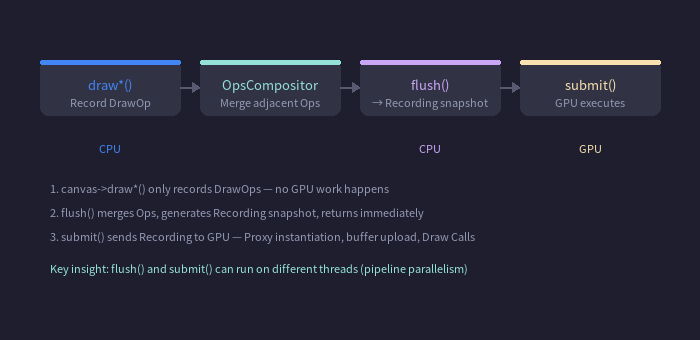
canvas->draw*() 的每次调用会生成一个 DrawOp,积累在 OpsCompositor 里。flush() 时统一处理:
canvas->drawRect(...) → 生成 RectDrawOp,入队
canvas->drawPath(...) → 生成 ShapeDrawOp,入队
canvas->drawTextBlob(...) → 生成 AtlasTextOp,入队
context->flush()
└→ DrawingManager::flush()
├─ OpsCompositor::makeClosed()
│ ├─ 分析队列,合并相邻同类 Op
│ └─ submitDrawOps() → 生成 RenderTask
└─ 返回 Recording(轻量快照,不执行 GPU 工作)
context->submit(recording)
└→ DrawingBuffer::encode()
├─ Proxy 实例化(延迟到此刻)
├─ 生成顶点缓冲
├─ 查找 / 编译 GPU Program
└─ 提交 Draw Call → GPU
四、Op 合并:减少 Draw Call 的核心
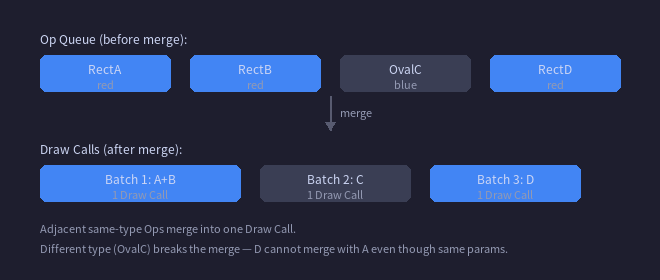
Draw Call 多了 GPU 吞吐跟不上,CPU 侧的提交开销也不可忽视。相邻的同类型 Op,如果 Paint 参数相同,就可以合并为一次 Draw Call——把多个矩形的顶点数据打包进同一个缓冲区,一次提交全部画完。
OpsCompositor 分析 Op 队列,把满足条件的相邻 Op 合并:
| Op 类型 | 合并条件 |
|---|---|
RectDrawOp | 相同 Paint(Shader / BlendMode / ColorFilter) |
RRectDrawOp | 相同圆角参数和 Paint |
AtlasTextOp | 来自同一纹理图集,相同 BlendMode |
ShapeDrawOp | 相同填充规则和 Paint |
MeshDrawOp | 相同纹理和 BlendMode |
有一点需要注意:合并只能在相邻的同类 Op 之间发生。中间插了一个不同类型的 Op,就会打断合并:
[红色矩形A] [红色矩形B] [蓝色圆形C] [红色矩形D]
合并结果:
批次1: A+B(合并) → 1 次 Draw Call
批次2: C → 1 次 Draw Call
批次3: D → 1 次 Draw Call
D 哪怕跟 A 参数一样,也无法跨越 C 合并。打断合并的常见原因:不同类型的 Op 穿插、BlendMode 切换、触发 saveLayer 的 ImageFilter。
五、Proxy:资源按需分配
什么时候把图像上传到 GPU 最合理?调用 Image::MakeFromFile 时立刻上传?
不合理。应用层可能创建大量 Image 对象,但大部分在当前帧根本不会被渲染。提前上传浪费显存,上传本身也有 I/O 和编解码开销。
GPU 资源的分配也是延迟的。Image::MakeFromFile 只创建一个 TextureProxy——一个占位符,记录「需要一张来自这个文件的纹理」的意图,不做任何实际工作。等到 OpsCompositor 真正需要这张纹理时,ProxyProvider 才触发解码和上传:
Image::MakeFromFile("photo.png")
↓
TextureProxy 创建(仅意图,无 GPU 内存)
...可能多帧不渲染这张图片...
canvas->drawImage(image)
↓
OpsCompositor 需要这张纹理
↓
ProxyProvider 实例化:解码 → 上传 GPU
↓
Texture(实际 GPU 内存分配)

三种 Proxy:
| Proxy | 对应 GPU 资源 |
|---|---|
TextureProxy | GPU 2D 纹理 |
RenderTargetProxy | 可写入的渲染目标纹理 |
GPUBufferProxy | 顶点 / 索引缓冲区 |
六、Recording:指令录制与异步提交
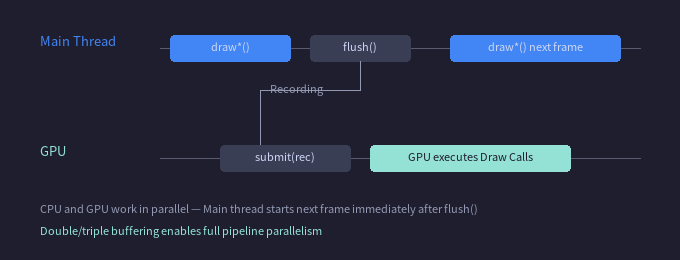
如果 flush() 同步等 GPU 执行完,主线程在这段时间什么都干不了。
解决方法是把"生成指令"和"执行指令"分开:flush() 生成一个 Recording 快照——将当前帧的所有渲染任务打包为一个轻量级的 ID 快照(关联到 DrawingBuffer),但不执行任何 GPU 工作。submit() 才真正执行 GPU 指令——在此阶段完成 Proxy 实例化、顶点上传、Program 编译和 Draw Call 提交。
主线程完成 flush 后立刻开始录制下一帧,不等 GPU 执行完。双缓冲或三缓冲模式下,CPU 和 GPU 可以完全流水线并行。
七、路径渲染与三角化
GPU 不能直接理解矢量路径(贝塞尔曲线、任意多边形),只能处理三角形。面对这个约束,TGFX 根据路径类型和场景选择不同策略,而不是一刀切:
| 策略 | 适用场景 | 核心方式 |
|---|---|---|
| 直接三角扇 | 矩形、椭圆等凸多边形 | 专用顶点生成,绕过通用三角化 |
| Coverage AA | 复杂曲线路径 | GPU 计算亚像素覆盖率,抗锯齿 |
| MSAA | 简单多边形 | 硬件多重采样 |
| Hairline | ≤1px 极细线 | GPU Shader 直接计算每像素覆盖率 |

矩形和圆角矩形是最高频的绘制对象,专用的顶点生成器完全绕过路径三角化,渲染开销接近于直接画一个四边形。
八、两种思路:Skia 通用化 vs TGFX 专注 GPU
TGFX 的目标很清晰:只跑在有 GPU 的场合。移动端和桌面端用真实的 GPU,服务端就用 SwiftShader 软件模拟。Skia 不一样,它要应付各种环境——没 GPU 的服务端、嵌入式设备,甚至纯 CPU 渲染也支持(SkBitmapDevice)。
因为定位不同,两个库在五个关键维度上走了完全不同的路。
渲染路径:双路径 vs 单路径
Skia 保留了完整的 CPU 软件渲染路径(raster backend),每个功能都要准备两套实现、两套测试。GPU 路径中还有 SoftwarePathRenderer 在 GPU 不支持时降级到 CPU。缓存层因此偏保守——数据可能要从 GPU 回到 CPU,不敢长期驻留。
TGFX 没这个包袱,所有中间结果直接留在 GPU 端,缓存策略更激进。资源默认常驻 GPU 直到超过过期帧数(默认 120 帧),不像 Skia 那样用 budgeted/non-budgeted 分层精细管理。
渲染线程:同步 vs 异步流水线
Skia 的 GrDirectContext::flush() 在调用时就完成指令编码和提交——flush 和 submit 绑定在同一次调用中。更关键的是,Skia 在 Debug 模式下用 ASSERT_SINGLE_OWNER 宏强制检查 flush/submit 必须在创建 Context 的线程上调用,不支持跨线程的录制-提交分离。
TGFX 把这两步拆开了:
flush()只生成一个轻量级的Recording快照(16 字节,仅包含 contextID、drawingBufferID、generation),立即返回submit(recording)在任意线程执行真正的编码——Proxy 实例化、顶点上传、Program 编译、Draw Call 提交
这使得 CPU 和 GPU 可以在不同线程上全流水线并行工作:主线程 flush 完立刻开始下一帧的录制,不需要等 GPU 执行完。
Uniform 数据:逐个传 vs UBO 缓冲
在 OpenGL 里传 Uniform 数据给 Shader 有两种方式:glUniform* 逐个传,或者用 UBO(Uniform Buffer Object)批量写入。
Skia GL 后端只使用 glUniform* 系列函数(glUniform1f、glUniformMatrix4fv 等),逐个传递。这规避了 UBO 的 CPU-GPU 同步风险,但每次调用都有开销。
TGFX 使用 UBO + 多重缓冲:多个 slot 轮流使用,CPU 写一个 slot 时 GPU 读另一个 slot,互不干扰。SlidingWindowTracker 追踪最近帧的 Buffer 用量,自动收缩过大的 Buffer,避免显存浪费。
跨线程资源释放:互斥锁 vs 无锁队列
非渲染线程(图片解码、动画回调等)释放 GPU 资源时,需要线程安全的回收机制。
Skia 通过 SkMessageBus 传递资源释放消息,内部用 SkMutex 互斥锁保护消息队列。高频场景下,锁竞争会阻塞渲染线程。
TGFX 用 ReturnQueue 封装了 moodycamel::ConcurrentQueue(业界公认的高性能无锁并发队列)。资源引用计数归零时,自定义删除器自动将节点入队,全程无锁。渲染线程在 flush 开头批量出队回收。
超期资源:直接删除 vs 降级保留
Skia 对超预算的资源采取直接删除策略——从 purgeable 队列中取出并释放,不做降级。
TGFX 更温和:当超期资源仍有外部引用且自身携带 ScratchKey 时,只移除 UniqueKey 绑定(降级为 scratch 资源),但保留在缓存中等待复用。只有完全无引用无键的资源才被真正删除。这避免了”刚释放完下一秒又要重建”的循环,在频繁创建销毁中等大小纹理的场景(动画、列表滚动)下显存利用率更高。
一张表总结差异
| 对比点 | Skia | TGFX | 效果 |
|---|---|---|---|
| 渲染路径 | CPU + GPU 双路径 | GPU‑only 单路径 | 缓存更激进,CPU↔GPU 传输减少 |
| 渲染线程 | flush 编码+提交一体化,强制单线程 | flush → Recording → submit,可跨线程 | CPU/GPU 全流水线并行 |
| Uniform | glUniform* 逐个传 | UBO 多重缓冲 | 每帧省去 Buffer 分配开销 |
| 资源回收 | SkMutex 互斥锁 | 无锁队列 ReturnQueue | 高频渲染不阻塞 |
| 超期资源 | 直接删除 | 降级为 ScratchKey 保留复用 | 减少重复分配 |
一句话总结:Skia 因为要支持没 GPU 的环境,设计上偏保守;TGFX 只跑在 GPU 上,可以一路激进。
完整流程时序图
应用层 Core 层 GPU 层 硬件
│ │ │ │
│ canvas->draw*(...) │ │ │
│─────────────────────>│ │ │
│ │ 生成 DrawOp │ │
│ │─────────────────────>│ │
│ │ │ Op 入队 OpsCompositor
│ context->flush() │ │ │
│─────────────────────>│ │ │
│ │ DrawingManager:: │ │
│ │ flush() │ │
│ │─────────────────────>│ │
│ │ │ Op 合并/批处理 │
│ │ │ 生成 RenderTask │
│ Recording 快照 │ │ │
│<─────────────────────│ │ │
│ │ │ │
│ context->submit(rec) │ │ │
│─────────────────────────────────────────────>│ │
│ (异步返回) │ │ Proxy 实例化 │
│ │ │ VtxBuffer 上传────>│
│ │ │ Program 编译/复用─>│
│ │ │ Submit DrawCall──>│ GPU执行