图层渲染系统
一、从最简单的情况说起
假设你只有一棵 Layer 树,要把它画到屏幕上。最直接的做法是:每帧从根节点开始遍历,把所有图层按顺序画一遍。
这就是 Direct 模式——没有缓存,没有中间纹理,遍历完立刻呈现到目标 Surface。
displayList->setRenderMode(RenderMode::Direct);
displayList->render(surface);
适合的场景:
- Layer Tree 很小、很浅(一个小 Widget,几层图层)
- 内容每帧全部在变(视频播放、Canvas 动画)——缓存了也用不上
- 冷启动、首帧渲染——不值得建立缓存状态
Direct 模式代码路径最短,开销最小。但它有一个天然的上限:每帧必须完整遍历整棵树,不管什么内容变没变。
二、问题出现:大部分帧什么都没变
在一个交互式编辑器里,用户每次操作通常只改动了一小块——移动了某个图层、修改了某段文字、加了一个特效。但 Direct 模式不管这些:只要触发重绘,整棵树都要跑一遍。Layer 数量多了之后,这个开销完全不可接受。
根本原因:Direct 模式没有记住上一帧的结果,每帧都从零开始。
三、脏区刷新:只重绘变化的部分
核心思想
记住上一帧的渲染结果;下一帧只重绘发生变化的区域,其他区域直接复用缓存。
这是 Partial 模式(默认模式)的核心机制。

当一个图层属性发生变化时,TGFX 自动计算它在画布上的投影矩形,标记为「脏区」。渲染时只处理脏区内的图层,脏区外的区域直接保留:
// 这些操作都会自动触发脏区标记,无需手动管理
layer->setPosition(Point::Make(100, 200));
layer->setAlpha(0.5f);
layer->setFilters({blurFilter});
blurFilter->setBlurrinessX(20.0f); // LayerProperty 修改也会传播脏区
Partial 模式适合的场景:
- 交互式编辑器(每次用户只改一处)
- 局部动画(某个图标在播放,其他内容静止)
- 属性动画(透明度/位置插值,影响范围局部)
- 文字输入(只有光标和当前行在变)
Partial 模式需要额外分配一块与目标 Surface 等大的缓存 Surface,用于保存上一帧结果。这是它相比 Direct 的唯一内存代价。
四、脏区的极限:大范围滚动缩放
Partial 在「局部变化」的场景下效果显著,但它有一个明显的弱点:
当画布大范围平移或缩放时,几乎所有区域都变成了「脏的」。
以一个 8000×6000 的设计文档为例,用户把视图从 100% 缩小到 50%:
缩放前:显示左上角 1920×1080 的内容
缩放后:需要显示 3840×2160 区域内的内容(缩小一半后填满屏幕)
脏区范围:整个屏幕 → 等同于全量重绘
更糟的是,缩放后视口对应更大面积的原始内容,需要遍历更多图层——比缩放前的全量重绘还慢。
根本原因:Partial 的缓存是以「像素坐标」为单位存储的,一旦坐标系变了,所有缓存都失效。
五、Tile 渲染:把画布切成小块
核心思想
不把整个画布当成一个缓存,而是切成均匀的小块(Tile),每块独立缓存自己的渲染结果。每帧只处理当前视口覆盖的那些 Tile。
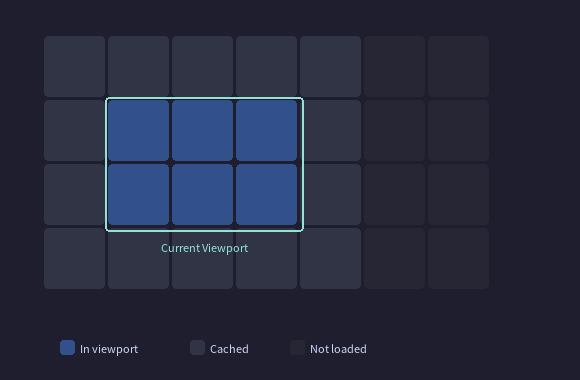
用 zoomScale 和 contentOffset 控制视口,比直接设 matrix 更高效——这两个属性的变化不会使图层树的内部缓存失效:
displayList->setRenderMode(RenderMode::Tiled);
displayList->setTileSize(256); // 每块 256×256,建议为 2 的幂次
displayList->setMaxTileCount(64); // 允许最多 64 块同时存在
// 平移和缩放通过这两个接口,不要用 root->setMatrix()
displayList->setZoomScale(0.5f);
displayList->setContentOffset(-400, -300);
滚动时:视口平移,进入视口的新 Tile 按需渲染,离开视口的 Tile 缓存保留(下次滑回来直接用)。
缩放时:每个 Tile 的缓存按 zoom 级别分开存储。缩放到新比例后,可以先用旧比例的 Tile 模糊填充(allowZoomBlur),后台按需更新到当前比例:
displayList->setAllowZoomBlur(true); // 缩放过渡时允许短暂模糊
displayList->setMaxTilesRefinedPerFrame(5); // 每帧最多更新 5 块到新精度
相邻 Tile 的渲染结果会打包进同一个纹理图集(Atlas),合并成单次 Draw Call 输出到屏幕,减少 GPU 通信次数。
Tile 模式适合的场景:
- 无限画布(设计工具、白板)
- 大文档滚动(长文档、大型表格)
- 多级缩放(5%~500% 自由缩放)
- Layer 数量成千上万的大型文件
六、Layer 缓存层次结构
上面讲的是「整帧如何渲染」的策略。在这之上,还有一层针对「静止子树」的缓存机制。
问题
Tile 缓存的单位是 Tile(一块屏幕区域),适合处理视口滚动和缩放。但有一类场景 Tile 解决不了:当缩放比很小时(比如 5%),整个 8000×6000 的画布缩小到屏幕上只有几百像素,但系统还是要遍历所有图层来生成这几百像素,大量计算用于渲染最终肉眼不可分辨的细节。
SubtreeCache:静止子树直接缓存为纹理
SubtreeCache 是一种子树级别的缓存:当一棵子树的所有图层都没有发生变化时,把它的渲染结果缓存为一张纹理。后续帧直接贴这张纹理,完全跳过子树的遍历和绘制。
// 设置子树缓存的最大尺寸(最长边,像素)
// 渲染尺寸小于这个值的静止子树会被缓存
displayList->setSubtreeCacheMaxSize(512);
缓存尺寸采用 mipmap 式对齐策略:以 maxSize 为基准,按 1/2、1/4、1/8…… 向下取整到最近的一档,而不是精确匹配当前渲染尺寸。
maxSize = 512
缩放到 100%,子树渲染尺寸 400px → 缓存到 512 档
缩放到 60%, 子树渲染尺寸 240px → 缓存到 256 档(512/2)
缩放到 30%, 子树渲染尺寸 120px → 缓存到 128 档(512/4)
缩放到 10%, 子树渲染尺寸 40px → 缓存到 64 档(512/8)
这个对齐策略避免了每次缩放都重新生成缓存纹理(只有跨越 2 倍档位时才更新),同时控制了纹理数量,防止显存碎片。
完整缓存层次
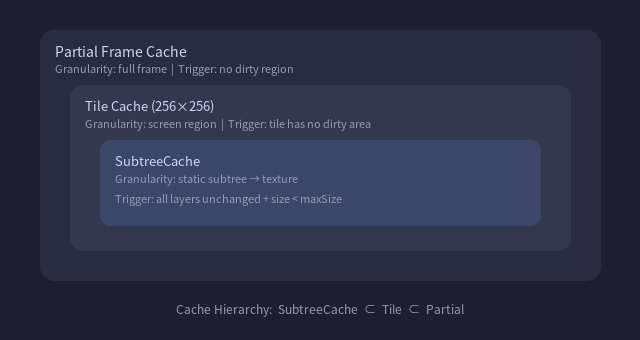
这三层缓存的颗粒度从小到大,适用场景互补:
- Partial 帧缓存:大多数交互场景(局部变化),默认开启
- Tile 缓存:大画布 + 滚动缩放
- SubtreeCache:Tile 模式下的小缩放比加速,以及深层静止子树的跳过优化
七、3D 图层渲染
问题:2D 合成模型下 3D 遮挡关系错误
2D 渲染下,图层系统按文档顺序(即 addChild 的顺序)从底到顶逐层绘制,后添加的图层始终覆盖在先添加的图层上方。即使给子图层设置了带 Z 轴分量的 matrix3D,父图层也只是把它当作 2D 仿射变换的投影结果来合成——图层间的遮挡顺序完全取决于文档顺序,与 Z 坐标无关。
这在 3D 动画场景里会出现明显的错误:两张卡片做绕 Y 轴旋转时,card2 旋转到"穿过"card1 的那一刻,按文档顺序 card2 始终在 card1 上面——视觉上是穿模,而不是两张卡片真实相交。
为什么不用 Z-buffer
最直接的想法是引入 Z-buffer:GPU 硬件支持,每个像素记录深度值,按像素级别决定遮挡,逻辑简单。
但 TGFX 的图层是带 alpha 通道的纹理,不是不透明的 3D 网格。Z-buffer 对半透明内容天然失效——半透明像素需要按从远到近的顺序混合,而 Z-buffer 只能做逐像素遮挡测试,不能正确处理混合顺序。强行用 Z-buffer 会导致半透明图层互相穿插时出现错误的混合结果。
为什么不用简单 Z 排序
另一个常见方案是把每个图层按 Z 中心深度从大到小排序,再按序绘制。这对非相交的图层完全正确,但当两个图层在 3D 空间中相交时,单一的 Z 排序无法确定谁先谁后——同一张卡片旋转到垂直位置时,它的一半在另一张卡片前面、另一半在后面,排序之后无论谁先画,都有一半画错。
解决:BSP 树做精确深度排序
TGFX 的实现在 Context3DCompositor 里,使用二叉空间分割树(BSP Tree)做 3D 深度排序。
核心思路:把每个图层的矩形区域看作一个 3D 多边形(DrawPolygon3D)。当两个多边形相交时,沿交线把其中一个切开,分成"在另一个前面的部分"和"在另一个后面的部分"——两个子片段就有了明确的前后关系,可以分别插入 BSP 树。
完整流程如下:
1. 每个子图层单独录制为 Picture → 转为 Image(纹理)
↓
2. 把 Image + Matrix3D 封装为 DrawPolygon3D(3D 多边形)
↓
3. 按 (depth, sequenceIndex) 预排序,构建 BSP 树
每次取第一个多边形作为分割平面,把其余多边形
分到 front / back,共面的分别放入 coplanarsFront 和 coplanarsBack 列表
↓
4. BSP 树 back-to-front 遍历(Painter's Algorithm)
按"先画远处、后画近处"的顺序提交 GPU Draw Call
↓
5. Context3DCompositor 把结果渲染到离屏 RenderTarget
再把这张合成图贴回父 Canvas
代码上的关键路径:
// Context3DCompositor::finish()
std::sort(_polygons.begin(), _polygons.end(), DrawPolygon3DOrder);
BspTree bspTree(std::move(_polygons));
bspTree.traverseBackToFront([this](const DrawPolygon3D* polygon) {
drawPolygon(polygon); // 按 BSP 序提交 GPU Draw Call
});
相交图层会在 splitAnother() 里被沿交线切开:原矩形被分成若干凸四边形(Quad),每个 Quad 独立参与 BSP 排序,再拼回正确的绘制顺序。
两条渲染路径
Layer3DContext::Make() 会根据当前是否处于不透明渲染上下文(opaqueContext != nullptr)选择两条路径:
路径一:Render3DContext(半透明内容,默认)
带 alpha 通道的图层走这条路。每个子图层独立录制 → 转为带透明度的 Image → 交给 Context3DCompositor 做 BSP 排序合成。最终所有图层在同一个离屏 RenderTarget 上按正确顺序混合。
路径二:Opaque3DContext(不透明渲染上下文)
当父图层已处于不透明渲染上下文中时不需要 BSP 排序——不透明内容互相遮挡不涉及混合顺序,直接按文档顺序依次应用 3D 矩阵绘制即可。这条路径省去了 BSP 树的构建和分割开销,速度更快:
// Opaque3DContext::finishAndDrawTo()
// no BSP, draw each offscreen image in order
for (const auto& entry : _opaqueImages) {
AutoCanvasRestore autoRestore(canvas);
canvas->concat(entry.transform.asMatrix());
canvas->drawImage(entry.image, &paint);
}
preserve3D 与 LayerStyle/Filter 的互斥
开启了 layerStyles、layerFilters、mask 或 scrollRect 的图层无法参与 3D 合成。原因在于:这些功能需要把图层先渲染到独立的离屏纹理、做后处理、再合成回父 Canvas——这是一个"先合成好这个图层,再往上叠"的操作,图层在进入父 Canvas 之前就已经完成了混合,无法再参与跨图层的深度排序。
3D 深度排序要求所有子图层保持"原始纹理 + 3D 变换"的形式,由 BSP 树统一决定绘制顺序,两个机制在架构上互斥。如果同时使用,TGFX 会忽略该图层的 3D 合成,退回到 2D 文档顺序。
API 示例
auto container = Layer::Make();
container->setPreserve3D(true); // 对子图层启用 BSP 深度排序
card1->setMatrix3D(Matrix3D::MakeRotate({0, 1, 0}, angle1));
card2->setMatrix3D(Matrix3D::MakeRotate({0, 1, 0}, angle2));
container->addChild(card1);
container->addChild(card2);
// card1/card2 相交时,BSP 树会把相交部分切开,确保正确的遮挡顺序
八、三种模式选择决策树

| 模式 | 内存开销 | 适合的变化模式 |
|---|---|---|
| Direct | 无额外缓存 | 全动态内容 |
| Partial | +1 帧 Surface 大小 | 局部变化(默认) |
| Tiled | +N 个 Tile 纹理 Atlas | 大画布滚动/缩放 |