文字图集渲染
海量文字的 GPU 缓存与渲染策略
在现代 GPU 渲染管线中,文字是一个特殊的存在——它既不是简单的几何图形,也不是普通的位图纹理,而是介于两者之间的大量微小、高频重复的光栅化单元。如何高效地将成千上万个字形(Glyph)渲染到屏幕上,是 2D 渲染引擎的核心挑战之一。
TGFX 采用 图集(Atlas) 机制解决这一问题:将字形的光栅化结果缓存为 GPU 纹理,通过空间管理和缓存策略避免逐帧重复渲染。与 Skia 等方案不同,TGFX 进一步引入了 多线程并发光栅化 管线,在命令记录阶段就将字形光栅化任务分派到线程池异步执行,在画布缩放等大量字形需要重新生成的场景下获得显著的性能优势。
为什么需要图集?
问题:逐字形渲染的性能瓶颈
一段中文文本可能包含数百个字形,每个字形从矢量轮廓到像素需要经历字形查找、轮廓解析、光栅化等 CPU 密集操作。如果每一帧都对每个字形重复执行这一流程,性能将无法接受:
每一帧 × 每个字形 → 光栅化 → 创建纹理 → 上传 GPU → 绘制
↑ CPU 密集 ↑ 总线开销 ↑ 状态切换
更糟的是,大部分字形在连续帧中并没有变化——同一段文字在屏幕上停留几秒钟,却要重复光栅化数百次。
解决思路:共享纹理图集
图集的核心思想很直接:把多个字形的光栅化结果拼接到同一张大纹理上,通过 UV 坐标索引每个字形的位置。
┌────────────────────────────────┐
│ A B C D E F G H I J │
│ K L M N O P Q R S T │
│ U V W X Y Z 0 1 2 3 │
│ 你 好 世 界 · · · · · · │
│ · · · · · · · · · · │
│ (空闲区域) │
└────────────────────────────────┘
Atlas 纹理 (2048×2048)
这样带来三个核心收益:
- 避免重复光栅化:每个字形只需光栅化一次,后续帧直接从图集中查找
- 减少纹理切换:数百个字形共享同一张纹理,GPU 只需绑定一次
- 批量绘制:相同纹理上的字形可以合并为一次 Draw Call
这是业界通用的方案。TGFX 的差异化在于:如何管理图集空间、如何决定渲染路径、以及如何利用多线程加速图集生成。
三级空间管理:Atlas → Page → Plot
图集空间管理的核心挑战是:在一张固定尺寸的纹理上,高效地为大小不一的字形分配和回收矩形区域。
TGFX 设计了一套三级空间管理体系:
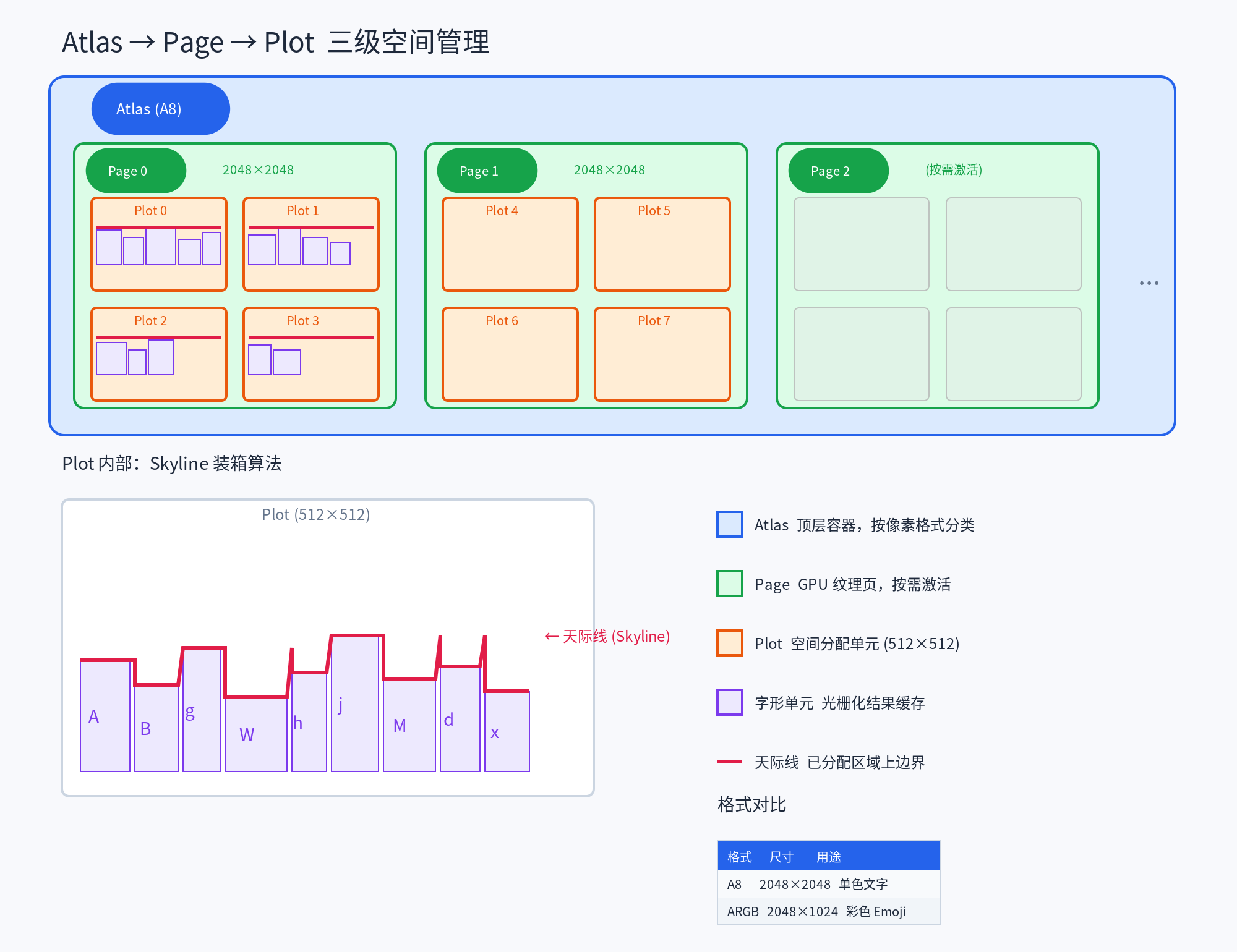
Atlas:顶层容器
Atlas 是按 像素格式 独立管理的顶层容器。TGFX 维护两种格式的 Atlas:
| 格式 | 用途 | 纹理尺寸 | 特点 |
|---|---|---|---|
| A8(Alpha8) | 单色文字、抗锯齿遮罩 | 2048 × 2048 | 每像素 1 字节,最省内存 |
| ARGB | 彩色 Emoji、彩色字形 | 2048 × 1024 | 每像素 4 字节,支持全彩色 |
每种格式的 Atlas 独立管理自己的页面池,互不干扰。
Page:GPU 纹理页
每个 Page 对应一张 GPU 纹理。页面采用 按需激活 策略——初始只有一个页面,当空间不足时才激活新页面:
时间 →
─────────────────────────────────
初始: [Page 0]
空间满: [Page 0] [Page 1] ← 激活新页面
继续满: [Page 0] [Page 1] [Page 2]
达到上限:[Page 0] [Page 1] [Page 2] [Page 3] ← 开始驱逐
Plot:空间分配单元
为什么不直接在 Page 上分配字形? 因为字形缓存需要淘汰——画布缩放、字体切换、页面跳转都会使大量旧字形失效。如果直接在 2048×2048 的 Page 上管理,淘汰单个字形意味着在纹理中"挖洞",产生大量碎片,空间利用率急剧下降。而整页回收又代价太大,一次清除数千个字形会导致后续帧大量缓存未命中。
Plot 的引入正是为了解决这个矛盾:将淘汰粒度控制在一个合适的中间尺度。回收一个 512×512 的 Plot 只影响其中的几十个字形,既避免了逐字形回收的碎片化问题,又不会像整页回收那样造成大面积缓存失效。Plot 重置后 Skyline 归零,空间完全干净,可以立即重新分配——没有碎片、没有空洞。
每个 Page 被划分为固定大小的 Plot(子区域)。以 A8 格式为例,2048×2048 的纹理被划分为 4×4 = 16 个 512×512 的 Plot:
Page (2048×2048, A8 格式)
┌────────┬────────┬────────┬────────┐
│Plot 0 │Plot 1 │Plot 2 │Plot 3 │
│512×512 │512×512 │512×512 │512×512 │
├────────┼────────┼────────┼────────┤
│Plot 4 │Plot 5 │Plot 6 │Plot 7 │
│ │ │ │ │
├────────┼────────┼────────┼────────┤
│Plot 8 │Plot 9 │Plot 10 │Plot 11 │
│ │ │ │ │
├────────┼────────┼────────┼────────┤
│Plot 12 │Plot 13 │Plot 14 │Plot 15 │
│ │ │ │ │
└────────┴────────┴────────┴────────┘
Plot 内部使用 Skyline 装箱算法(Skyline Bin Packing)为字形分配矩形空间。Skyline 算法维护一条"天际线"——已分配区域的上边界轮廓,新字形总是放置在天际线的最低点,像搭积木一样逐层向上填充:
Plot 内部 (512×512)
┌──────────────────────────┐
│ │ ← 可用空间
│ │
│ ┌──┐ │
│ ┌──┤ │ ┌─────┐ │
│ │A │B │ │ D │ │ ← 天际线 (Skyline)
│ │ │ ├──┤ ├──┐ │
│ │ │ │C │ │E │ │
└──┴──┴──┴──┴─────┴──┴────┘
为什么选择 Skyline 而非更复杂的装箱算法?
矩形装箱是一个经典的 NP-hard 问题,存在 MaxRects、Guillotine 等更高利用率的算法。TGFX 选择 Skyline 的理由是:
- 内存占用极低:Skyline 只需维护一条天际线轮廓(一个节点数组),而 MaxRects 需要维护所有空闲矩形的列表,Guillotine 需要维护递归切割产生的碎片树。对于 512×512 的 Plot,Skyline 的节点数通常只有几十个,内存开销可忽略不计
- 时间复杂度可控:单次分配 O(n²)(n 为天际线节点数),由于 Plot 尺寸有限且节点会合并,n 始终很小,实际表现接近常数时间
- 字形尺寸相对均匀:文字字形的宽高差异远小于一般的精灵图,Skyline 的空间利用率已经足够
- 无需回收碎片:Plot 整体回收而非单个字形回收,Skyline 天然适合这种"只分配不释放"的模式
字形定位:AtlasLocator
每个缓存在图集中的字形通过 AtlasLocator 记录其精确位置:
AtlasLocator
├── pageIndex → 在哪一页纹理上
├── plotIndex → 在哪个 Plot 中
└── rect (x,y,w,h) → Plot 内的像素坐标
渲染时,通过 AtlasLocator 可以直接计算出 UV 纹理坐标,完成字形到屏幕的映射。
三级回退渲染策略
并非所有文字都适合通过图集渲染。TGFX 设计了三种渲染路径,根据字形的实际情况自动选择最优策略:
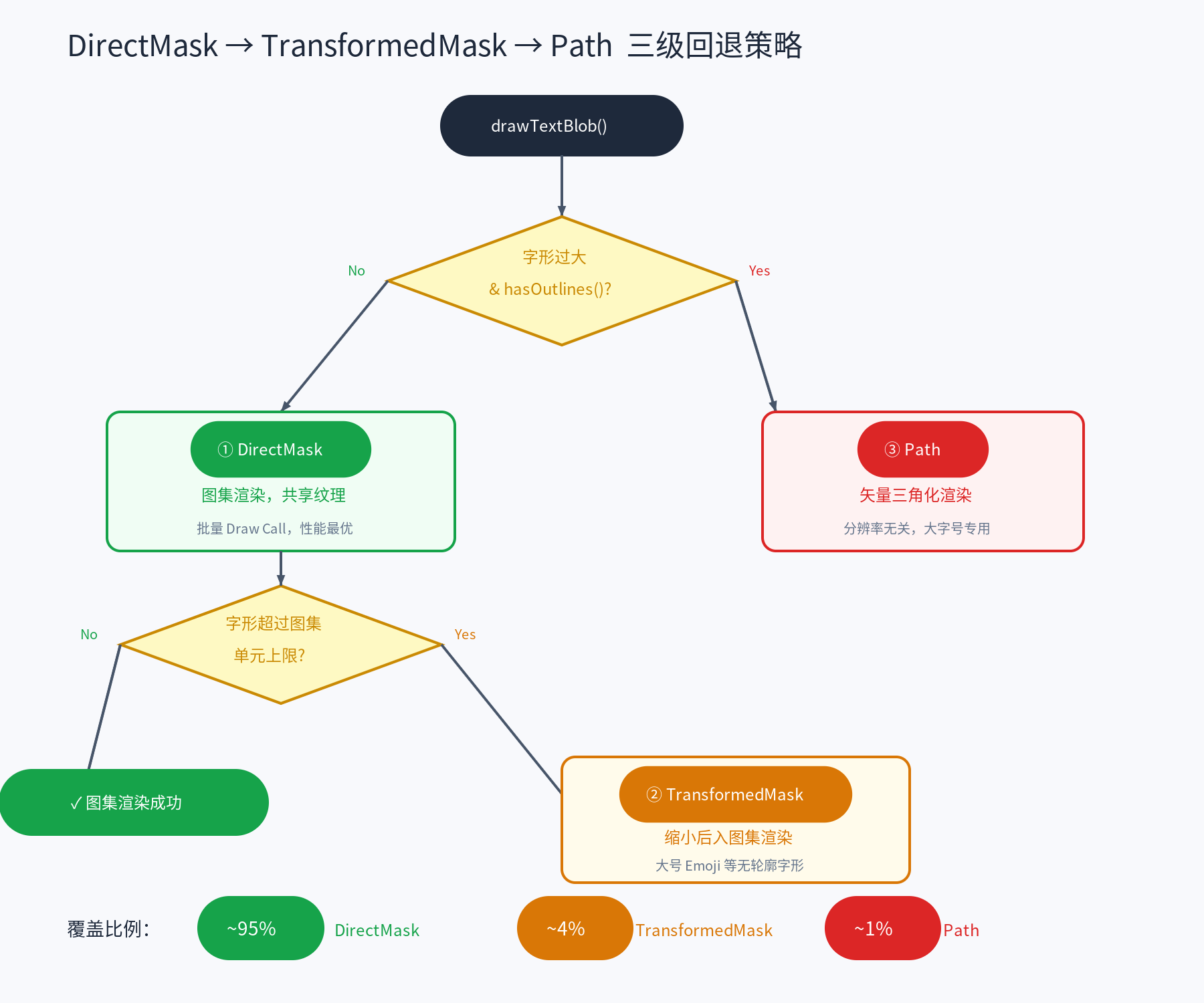
TGFX 首先判断字形是否过大且具有矢量轮廓,如果是则直接走 Path 矢量渲染;否则走 DirectMask 图集渲染。DirectMask 中如果字形超过图集单元上限,则回退到 TransformedMask 缩小后渲染。
路径一:DirectMask(图集渲染)—— 默认路径
触发条件:字形在当前变换矩阵下的实际渲染尺寸不超过 256×256 像素。
这是最高效的路径。字形按照 屏幕像素尺寸 光栅化后缓存到图集中,抗锯齿在光栅化阶段已经完成。渲染时直接使用 Point(Nearest)采样贴图,像素一一对应,不存在缩放模糊问题。
关键设计:缩放感知的缓存 Key
字形的缓存键包含了视图矩阵的缩放分量。同一个"A"字在 1x 和 2x 缩放下会生成两个不同的缓存条目:
缓存 Key = (GlyphID, ScalerContext特征, Font参数, 缩放因子)
"A" @ 1x → 光栅化为 12×16 像素 → 缓存条目 1
"A" @ 2x → 光栅化为 24×32 像素 → 缓存条目 2
这意味着画布缩放会导致大量缓存未命中。这正是多线程并发光栅化的核心价值所在——后文详述。
路径二:TransformedMask(缩小渲染)—— 回退路径
触发条件:DirectMask 路径中,字形在当前缩放下的渲染尺寸超过了 256×256 像素。典型场景是大号 Emoji——Emoji 字体没有矢量轮廓(hasOutlines() 为 false),无法走 Path 路径,但字号又很大,单个字形的像素尺寸超过了 256×256 的限制。
TransformedMask 会将字形 缩小到图集单元能容纳的尺寸 后光栅化,再通过 GPU 纹理采样放大渲染。虽然存在一定的缩放模糊,但对于没有矢量轮廓的字体这是唯一选择。
路径三:Path(矢量渲染)—— 大字号路径
触发条件:字形在当前缩放下的渲染尺寸超过了 256×256 像素,且字体具有矢量轮廓(hasOutlines())。
对于大字号或高倍缩放的文字,将字形光栅化为位图既浪费内存又不划算。此时 TGFX 直接使用字形的矢量轮廓(Path),通过三角化后交给 GPU 渲染。
这条路径的优势是 分辨率无关——无论缩放到多大,矢量轮廓始终保持清晰。注意,如果字体没有矢量轮廓(如 Emoji 字体),无论字形多大都无法走此路径,只能回退到 TransformedMask。
为什么需要三级回退?
这个设计的出发点是 用最小的代价覆盖最大的场景:
| 路径 | 适用场景 | 代价 | 覆盖比例 |
|---|---|---|---|
| DirectMask | 常规字号 + 常规缩放 | 最低(图集共享纹理) | ~95% |
| TransformedMask | 字形超过 256×256(大号 Emoji 等) | 中等(缩小后渲染,有模糊) | ~4% |
| Path | 字形超过 256×256 + 有矢量轮廓 | 较高(矢量三角化) | ~1% |
绝大多数情况下,文字都走 DirectMask 路径。只有当字形渲染尺寸超过 256×256 时才需要回退——有矢量轮廓的走 Path 保持清晰,没有轮廓的走 TransformedMask 缩小后渲染。
多线程并发光栅化:核心差异化设计
这是 TGFX 与 Skia 在文字图集渲染上最根本的架构差异。
Skia 的同步模型
在 Skia 的渲染管线中,字形光栅化和图集上传是 同步执行 的——在绘制命令处理阶段,遇到未缓存的字形时,当前线程会立即执行光栅化,生成像素数据后直接上传到 GPU 纹理。这意味着如果有 N 个字形需要光栅化,主线程会被阻塞 N 次,总耗时是所有字形光栅化时间之和。
TGFX 的异步并发模型
TGFX 将这个流程拆分为 三个阶段,其中光栅化阶段完全异步执行:
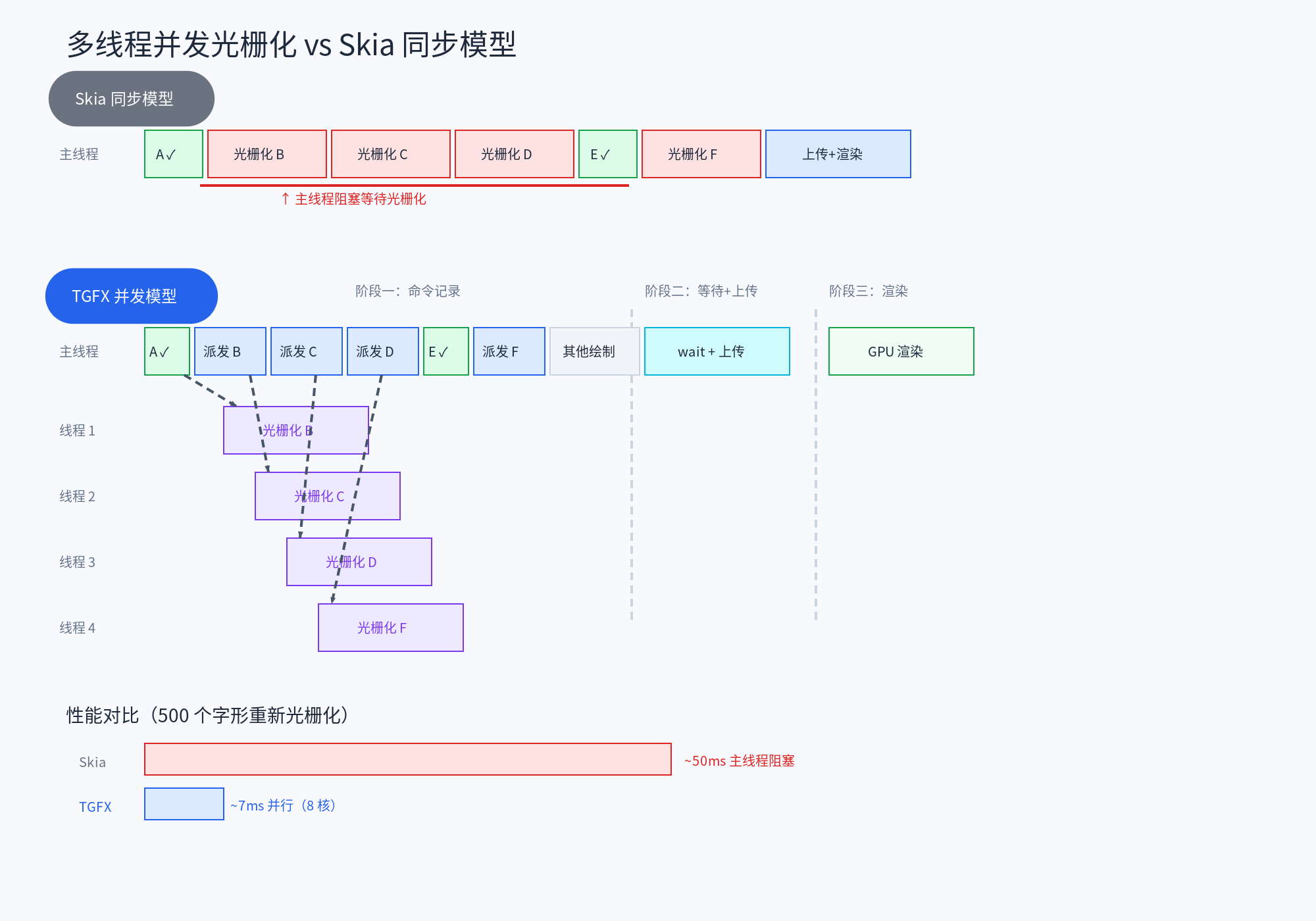
三个阶段的核心特征:
| 阶段 | 执行位置 | 做什么 | 是否阻塞 |
|---|---|---|---|
| 命令记录 | 主线程 | Atlas 空间分配 + 派发光栅化任务 | 不阻塞 |
| 并发光栅化 | 线程池 | CPU 执行字形光栅化 | 后台并行 |
| 上传与渲染 | 主线程 | 等待 + GPU 上传 + Draw Call | 短暂等待 |
为什么这个设计在缩放场景下优势巨大?
当用户通过手势缩放画布(Pinch-to-Zoom)时,所有字形的缓存都会因为缩放因子变化而失效,需要重新光栅化。假设屏幕上有 500 个可见字形,每个字形光栅化耗时 0.1ms:
Skia(同步): 500 × 0.1ms = 50ms 阻塞主线程
↑ 可能导致掉帧
TGFX(8 线程并发): 理论 500 / 8 × 0.1ms ≈ 6ms
+ 线程调度开销 + 上传时间
≈ 7ms 后台执行
↑ 主线程几乎不阻塞
考虑到线程调度、锁竞争、缓存一致性等实际并发开销,实际加速比不会精确达到理论上的 1/8,但仍能大幅提升性能。更重要的是,光栅化与后续绘制命令的记录是并行的——主线程在派发完光栅化任务后,可以立即继续处理其他绘制命令(矩形、图片等),最大化 CPU 利用率。
线程池与任务调度
TGFX 使用一个全局线程池管理所有异步任务(不仅限于字形光栅化)。线程池的设计追求低开销和高吞吐:
TaskGroup(全局单例)
├── 线程数 = 物理 CPU 核心数(上限 32)
├── 3 级优先级队列:High / Medium / Low
├── 无锁并发队列(lock-free concurrent queue)
├── 按需创建线程:只在没有空闲线程时才创建
└── 超时回收:空闲 10 秒后线程自动退出
字形光栅化任务以 Medium 优先级提交。每个任务完全独立(不同字形之间没有依赖关系),天然适合并行化。
Work-Stealing 式等待
在 submit 阶段等待异步任务完成时,TGFX 使用了一个巧妙的优化:如果某个光栅化任务还在队列中排队(尚未被任何工作线程执行),等待线程会直接 在当前线程执行 该任务,而不是被动等待。
wait() 的智能行为:
├── 任务已完成 → 立即返回
├── 任务在执行中 → 阻塞等待完成
└── 任务还在排队 → 偷取到当前线程执行(避免无谓等待)
这种 Work-Stealing 策略确保了:即使在极端情况下(线程池繁忙、大量任务排队),等待时间也不会被浪费——等待线程自己也在做有用的工作。
HardwareBuffer 零拷贝优化
在支持 HardwareBuffer 的平台(如 Android)上,TGFX 进一步优化了 CPU 到 GPU 的数据传输。光栅化任务直接将像素数据写入 GPU 可访问的共享内存,跳过了传统的 writeTexture 拷贝步骤:
传统路径: CPU 光栅化 → CPU Buffer → [拷贝] → GPU Texture
零拷贝路径: CPU 光栅化 → HardwareBuffer (CPU/GPU 共享内存) → GPU 直接访问
缓存分层与淘汰机制
图集空间是有限的,而应用在运行过程中可能遇到成千上万个不同的字形。TGFX 设计了多层缓存策略来平衡命中率和内存占用。
AtlasStrike:缓存条目的组织单位
字形缓存以 AtlasStrike 为单位组织。一个 Strike 对应一组特定参数下的字形集合:
AtlasStrike = (ScalerContext 特征, Font 参数, 缩放因子) → { glyph 缓存表 }
例如:
Strike 1: (NotoSans, 14px, 1.0x) → { A→loc1, B→loc2, C→loc3, ... }
Strike 2: (NotoSans, 14px, 2.0x) → { A→loc4, B→loc5, C→loc6, ... }
Strike 3: (Emoji, 16px, 1.0x) → { 😀→loc7, 😂→loc8, ... }
AtlasStrikeCache:两级缓存结构
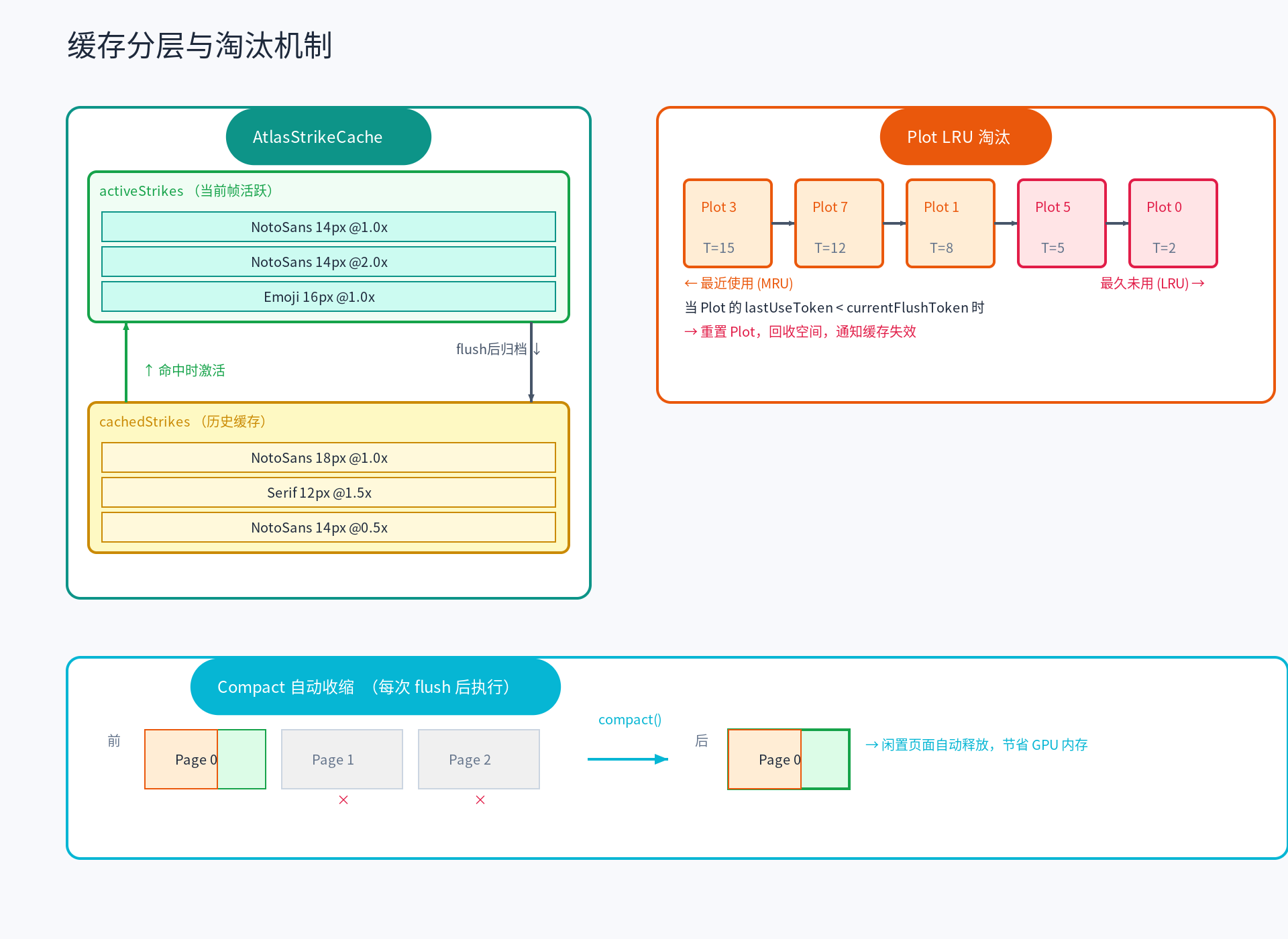
缓存流程:
- 查找:先在 activeStrikes 中查找,未命中则查找 cachedStrikes
- 激活:cachedStrikes 命中的 Strike 会被移到 activeStrikes
- 归档:每次 flush 后,activeStrikes 中的条目转入 cachedStrikes
- 淘汰:当图集空间回收时,受影响的 Strike 被从 cachedStrikes 中清除
Plot 级 LRU 淘汰
图集空间的淘汰以 Plot 为粒度。每个 Plot 维护一个"最后使用时间"(以 flush token 计量),当需要回收空间时,遍历所有页面的 Plot 链表(按 LRU 排序),找到最久未使用的 Plot,如果其最后使用时间早于当前 flush,则重置该 Plot(清除所有字形缓存),通知 AtlasStrikeCache 失效相关条目,使其变为可用。
Compact:自动收缩
除了被动淘汰,TGFX 还在每次 flush 后执行 compact(压缩) 操作,主动回收长期未使用的资源——对每个页面的每个 Plot,如果连续 N 次 flush 未被使用则重置回收空间;如果页面内所有 Plot 都已被重置,则停用该页面并释放 GPU 纹理。
这个机制确保了图集不会随着时间推移而持续膨胀——当应用场景切换(比如从文字密集的页面跳转到图片页面),不再需要的图集页面会自动释放。
与 Skia 的设计对比
| 设计维度 | TGFX | Skia |
|---|---|---|
| 光栅化模型 | 异步多线程并发(Task 派发到线程池) | 同步单线程(在命令处理时阻塞执行) |
| 图集页数 | 每种格式独立管理,共可使用多张纹理 | 全局共享,受限于固定页数 |
| 空间分配 | Skyline 装箱 + Plot 子区域划分 | 类似的 Plot 划分 + Skyline |
| 淘汰粒度 | Plot 级 LRU + 自动 compact 收缩 | Plot 级 LRU |
| 缓存组织 | AtlasStrike 两级缓存(active + cached) | GrTextStrike 单级缓存 |
| GPU 上传 | 支持 HardwareBuffer 零拷贝 | 传统 writeTexture 拷贝 |
| 渲染回退 | DirectMask → TransformedMask → Path 三级 | 类似的多级回退 |
为什么 TGFX 选择了异步模型?
Skia 的同步模型有其合理性——在桌面和浏览器场景下,文字渲染通常不是性能瓶颈,同步模型的实现更简单、调试更容易。
TGFX 选择异步模型的出发点不同:
- 移动端场景:TGFX 主要服务移动应用(PAG 动效、视频编辑),这些场景下画布缩放、列表滑动时可能同时有大量文字需要重新光栅化
- 多核利用:现代移动设备普遍拥有 4-8 个 CPU 核心,同步模型只能利用一个核心
- 帧率敏感:移动应用对 60fps 甚至 120fps 的要求更严格,单帧 50ms 的光栅化阻塞是不可接受的
代价是 实现复杂度更高——需要处理任务调度、同步等待、内存分配的线程安全等问题。但对于 TGFX 的目标场景,这个复杂度是值得的。
为什么不限于固定页数?
Skia 在同一种格式下限制使用固定数量的 Atlas 页面,当页面用满后只能通过驱逐来腾出空间。这在桌面浏览器等场景下是合理的——文字量通常有限,4 页已经足够。
TGFX 允许每种格式独立管理多个页面,总纹理数更灵活。这是因为:
- 图集渲染后清理:TGFX 的 compact 机制在每次 flush 后主动回收闲置页面,不会无限膨胀
- 移动端字符集更大:中日韩文字的字符集远大于拉丁字母,4 页可能不够覆盖一屏文字
- 缩放场景的突发需求:画布缩放时会同时需要大量不同尺寸的字形,短期内需要更多空间
完整渲染管线
将以上所有机制串联起来,一次文字绘制的完整流程如下:
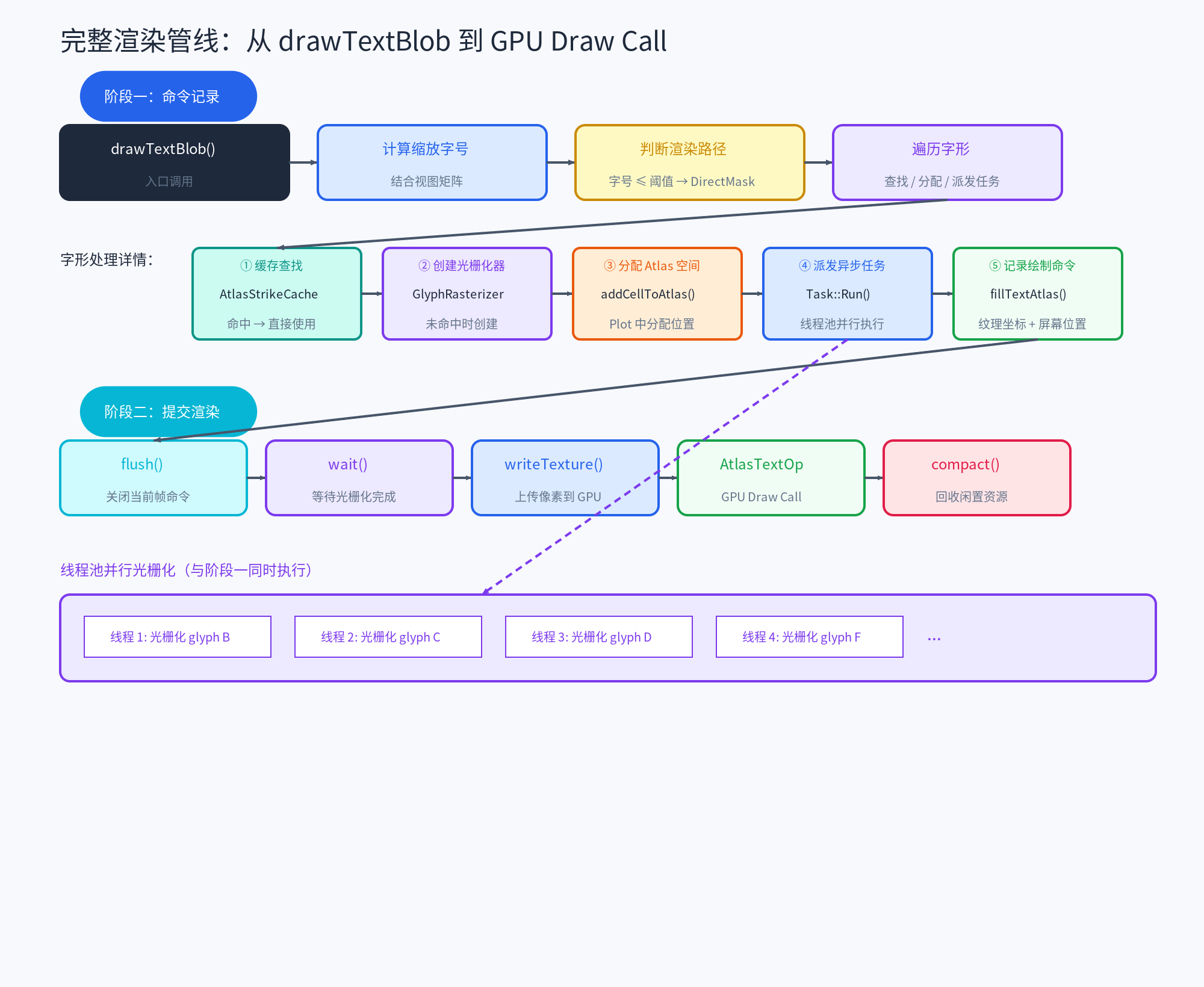
总结
TGFX 的文字图集渲染系统围绕三个核心设计决策构建:
三级空间管理(Atlas → Page → Plot) 在内存效率和分配速度之间取得平衡,Skyline 装箱算法满足字形尺寸相对均匀的特点,Plot 粒度的回收避免了碎片化管理的复杂度
三级渲染回退(DirectMask → TransformedMask → Path) 用最小代价覆盖最大场景,95% 的文字走图集路径享受批处理优势,极端场景有可靠的回退保障
多线程并发光栅化 是最核心的差异化设计。通过将光栅化任务异步派发到线程池,TGFX 在画布缩放、列表滑动等大量字形缓存失效的场景下,能够充分利用多核 CPU 的并行能力,将光栅化耗时降低到近似 1/N(N 为核心数),保障高帧率渲染